Cold email tools have a leverage problem. You write a cold.md policy once - voice, sequence, proof, banned phrases - and the system uses it forever. Your replies, opens, bounces accumulate as data nobody reads. Six months later you're still sending the same opener that worked on day one and quietly stopped working in week three.
cold.md is an open spec for that policy file. The new release adds something specific: the policy edits itself.
This post walks through what we shipped, why it matters, and how to run it against your own FoxReach account.
What's new
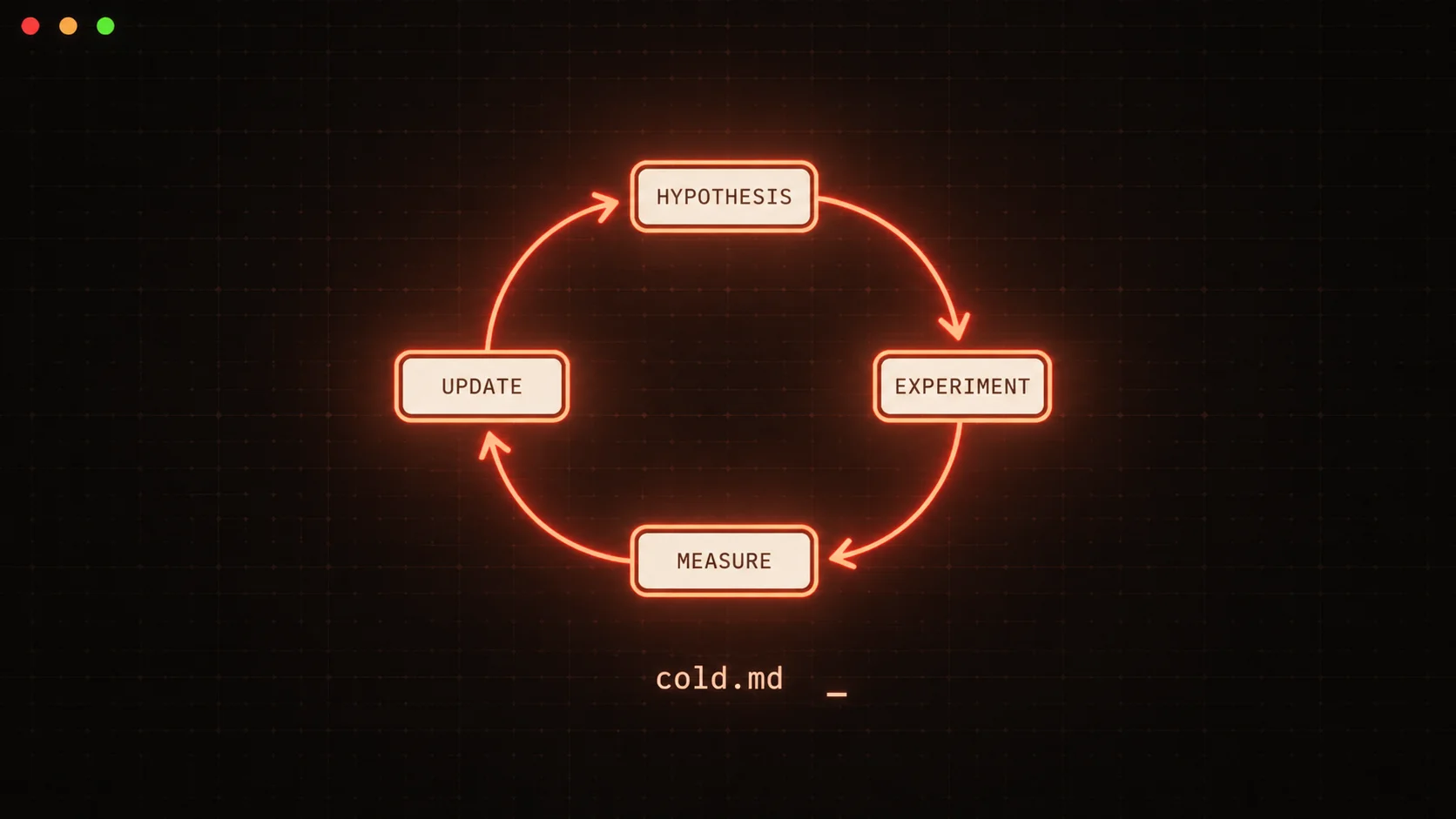
A self-improving loop, structured as four stages:
- Hypothesis. The agent picks the next variable to test (subject pattern → opener → CTA → cadence → tone).
- Experiment. It writes a protocol with arm definitions, sample size, and a success criterion (frequentist z-test, p<0.05, |delta|>2pp).
- Measure. After the minimum window, it pulls per-variant categorize-stats from FoxReach's new
/api/v1/inbox/categorize-stats?groupBy=variantendpoint. - Update. If a winner is declared, it proposes a
cold.mddiff for human review. After three approved diffs in a row, auto-commit unlocks.
The agent never blows up your sender reputation chasing a local optimum. Bounce rate over 5% on either arm pauses the variant immediately and halts experiment progression.
Why interested-reply rate, not opens
FoxReach doesn't track opens. Open-pixel tracking is the single largest cause of deliverability problems with Gmail and Outlook in 2026 - the pixel itself is a spam signal. So the metric we optimize for is interested-reply rate: AI-categorized inbound replies tagged "interested" divided by total sends per variant.
It's a slower signal. It's also a better one. Opens measure curiosity. Interested replies measure intent.
The two new skills
Out of the ten skills in the suite, two run the loop:
/cold experiment reads .cold/config.json, picks the current tier (Tier 1 = subject lines for v0), drafts two arm specs, declares sample size and decision rule, and writes a protocol to .cold/experiments/<id>/protocol.md.
/cold learn runs after the minimum window. It pulls categorize-stats from FoxReach, runs a two-proportion z-test on interested-reply rate, checks the bounce-rate guard, decides winner / inconclusive / extend, and writes either an .cold/proposed-diff.patch (default) or applies it directly (after trust earned).
Two more skills support them: /cold offer refines the value prop via competitor + market web research, and /cold status prints a one-screen dashboard of beliefs, active experiments, and pending diffs.
The variable tier ladder
Tiers must be tested in order. Earlier tiers must reach a stable winner before later ones unlock - otherwise the agent is optimizing the CTA on top of a still-noisy subject baseline.
| Tier | Variable | Min sample/arm | Time to read |
|---|---|---|---|
| 1 | Subject pattern | 100 | 7 days |
| 2 | Opener template | 150 | 10 days |
| 3 | CTA framing | 200 | 14 days |
| 4 | Cadence | 300 | 21 days |
| 5 | Voice tone | cohort | 30+ days, manual unlock |
For most v0 users, Tier 1 alone is the entire ROI: a +3 percentage-point lift in interested-reply rate over a 200-lead cohort compounds into measurable booked-call delta within a month.
What FoxReach added
Two backend changes shipped to support this:
/openapi-public.json- filtered to/api/v1/*paths only withAccess-Control-Allow-Origin: *. The agent reads this on every cold start to ground itself in the live API surface. Internal routes (/api/auth,/api/admin,/api/billing, etc.) never appear.GET /api/v1/inbox/categorize-stats- groups Reply categories (interested / not_interested / out_of_office / bounce / uncategorized) plus sent counts by variant, sequence, or day. JoinsReply.originalEmailLogIdagainstEmailLogso each reply is correctly attributed to the variant that produced it.
Both are documented at docs.foxreach.io/api-reference. The Python CLI (pip install foxreach-cli, v0.3.0+) wraps the new endpoint as foxreach inbox categorize-stats.
The trust ladder
Auto-rewriting your sender voice is dangerous. Doing it via diffs you can git apply is fine.
When cold-learn declares a winner, it doesn't edit cold.md. It writes:
.cold/proposed-diff.patch
…and prints:
Review: cat .cold/proposed-diff.patch
Accept: git apply .cold/proposed-diff.patch && rm .cold/proposed-diff.patch
Reject: rm .cold/proposed-diff.patch
A counter at .cold/trust.json tracks consecutive approvals. When you've accepted three diffs in a row, auto-commit unlocks. Reject one and the streak resets to zero.
This pattern matters for two reasons. First, you stay in the loop while the agent is learning your domain. Second, the audit trail is just git log - every policy change has a human approval and a measured experiment behind it.
Web research
Two surfaces use web search, both gated by config.
Policy-level (always-on): /cold icp validates your ICP by searching for competitor companies, target-title job postings, pain language on Reddit, and case-study patterns. /cold offer searches competitor pricing, recent funding, and differentiation gaps to refine the one-sentence value statement.
Per-lead (config flag): if you opt in at /cold init, /cold leads runs up to 2 searches per prospect (recent activity + company news) and saves findings to .cold/research/lead-personalization/<email-hash>.md. /cold draft reads these to inject specificity into the opener. Off by default - it's a real cost (one extra Claude call per lead).
Running it
# One-time setup
pip install foxreach-cli # v0.3.0+
export FOXREACH_API_KEY=otr_...
# In your project root
mkdir my-outreach && cd my-outreach
claude # Claude Code
> /cold init # 6-question wizard
> /cold icp https://your-company.com # who
> /cold offer # what (with competitor research)
> /cold leads --csv ./prospects.csv # ICP-score + import
> /cold experiment # design Tier 1 A/B
> /cold draft # variant pairs
> /cold send # ship via FoxReach (full pre-flight)
# Wait 7 days. Triage runs daily.
> /cold learn # propose cold.md diff
> /cold status # dashboard
> /cold report weekly # human digest
The full plugin install:
curl -fsSL https://cold.md/install | bash
The spec is open (CC-BY-4.0). The plugin is MIT. Source: github.com/concaption/cold-md.
What's next
Three things on the v0.3 roadmap:
- Bayesian decision rule. Frequentist z-tests are honest with n≥100 per arm but punishing with n=50. Beta posteriors give you "probability A>B" at any sample size.
- Multi-armed bandit mode. For workspaces happy to delegate more, replace the fixed 50/50 with adaptive weighting that shifts traffic toward the leading arm during the experiment, with exploration noise.
- Per-lead deeper research. Right now per-lead search is light (2 queries). v0.3 will optionally run a deeper agent loop - LinkedIn activity, recent job change detection, public commits - for high-value leads only.
If you're running outbound and want a system that gets better instead of one that quietly degrades, give it a try. Your cold.md is portable - the agent that improves it doesn't have to be FoxReach's. We just happen to be the reference implementation.
Related reading
- What is an AI SDR? A 2026 Definition - the broader category cold.md autoresearch sits inside
- Cold email to Google inbox in 2026 - the deliverability constraints that make interested-reply-rate the right metric
- What is MCP - how Claude Code talks to FoxReach under the hood